Agenti AI: perché “più” non significa “meglio” (e come farli lavorare in azienda)
- Andrea Viliotti

- 2 feb
- Tempo di lettura: 8 min
Una nuova ricerca propone leggi di scala per i sistemi multi‑agente: quando la coordinazione crea valore — e quando diventa puro overhead. Traduzione operativa per chi deve decidere architetture, KPI e controlli.
C’è un’idea seducente dietro gli agent systems: se un modello sa ragionare, allora un “team” di modelli — coordinato come un’organizzazione — dovrebbe ragionare meglio. Il lavoro “Towards a Science of Scaling Agent Systems” (arXiv:2512.08296v2) prova a togliere romanticismo e sostituirlo con misure: quando il multi‑agente scala, quando si rompe e quali metriche anticipano il punto di rottura.
Lo studio è firmato da un gruppo tra Google Research, Google DeepMind e MIT: Yubin Kim, Ken Gu, Chanwoo Park, Chunjong Park, Samuel Schmidgall, A. Ali Heydari, Yao Yan, Zhihan Zhang, Yuchen Zhuang, Yun Liu, Mark Malhotra, Paul Pu Liang, Hae Won Park, Yuzhe Yang, Xuhai Xu, Yilun Du, Shwetak Patel, Tim Althoff, Daniel McDuff e Xin Liu. Il messaggio operativo per imprese italiane (manifattura; servizi professionali; finanza‑assicurazioni; retail‑logistica; IT‑software) è chiaro: prima di investire in architetture complesse, occorre selezionare i task “eleggibili”, definire KPI osservabili e mettere in sicurezza strumenti e permessi (Kim et al., 2025).

Che cosa dice lo studio (senza marketing)
Gli autori partono da un fatto che chi implementa agenti conosce bene: oggi molta “best practice” è fatta di euristiche, non di leggi. Per costruire una base più scientifica, definiscono la performance agentica come interazione tra: quantità di agenti, struttura di coordinazione, capacità del modello di base e proprietà del compito. In altre parole: non esiste un “sistema migliore” in astratto; esiste un sistema che paga (o non paga) su una classe di task.
La parte rilevante è il disegno sperimentale: strumenti standardizzati, prompt standardizzati e budget di token standardizzati, per isolare l’effetto architettura da confondenti implementativi (Periodo: esperimenti nello studio; Fonte: Kim et al., 2025). Le architetture confrontate sono cinque: Single‑Agent System (SAS) e quattro famiglie multi‑agente (Independent, Centralized, Decentralized, Hybrid).
La valutazione avviene su quattro benchmark agentici che forzano multi‑step + tool use: Finance‑Agent, BrowseComp‑Plus, PlanCraft e Workbench (Kim et al., 2025). Lo studio attribuisce a ciascun dominio un indicatore di complessità D: Workbench 0,000; Finance‑Agent 0,407; PlanCraft 0,419; BrowseComp‑Plus 0,839 (Fonte: Kim et al., 2025, Tab. 10). Questo D è la chiave, perché sposta la discussione da “quale architettura” a “quale tipo di lavoro”.
Il dato che cambia la priorità: soglia di complessità e costo di coordinazione
La tesi centrale è brutale: esiste una soglia di complessità oltre la quale “mettere più agenti” peggiora. Nell’analisi degli autori la soglia critica è D ≈ 0,40 (Periodo: analisi nello studio; Fonte: Kim et al., 2025, App. C.3). Sotto quel valore, il task è abbastanza decomponibile da far valere il parallelismo; sopra, la coordinazione consuma le risorse che servono al ragionamento.
Per un decisore la traduzione è semplice: prima di scegliere vendor e framework, bisogna scegliere i processi. Non “dove l’AI è utile”, ma “dove la decomposizione è vera”: output verificabili, dipendenze limitate, strumenti con effetti reversibili o controllabili. È una scelta che vale in manifattura (anomalie qualità, manutenzione, pianificazione), nei servizi professionali (ricerca e sintesi di fascicoli, drafting controllato), in finanza‑assicurazioni (raccolta evidenze, triage, documentazione), in retail‑logistica (gestione eccezioni, routing, planning), e nell’IT (incident response, change analysis) — purché ci sia una ground truth o una procedura di verifica.
Il secondo risultato è che l’overhead non è un difetto “di implementazione”: cresce con la topologia. Lo studio misura un overhead O% di 58 (Independent), 263 (Decentralized), 285 (Centralized), 515 (Hybrid), a parità di budget medio μ = 4.800 token per trial (Periodo: esperimenti, n=180 configurazioni; Fonte: Kim et al., 2025, Tab. 5). Tradotto: più “governance conversazionale” inserite tra agenti, più spendete per parlare invece che per risolvere.
Terzo: l’errore può amplificarsi come in una catena di montaggio senza controlli qualità. Nelle metriche di coordinazione, l’Error Amplification Ae è 17,2× per Independent e 4,4× per Centralized. Se manca un meccanismo di verifica/containment, un errore piccolo diventa un errore “istituzionale” perché viene propagato e razionalizzato lungo il workflow.

Due ulteriori effetti completano il quadro. Primo: quando il baseline single‑agent è già “alto”, la coordinazione rende meno. Nel paper gli autori osservano una saturazione: oltre una soglia empirica di ~45% di performance del single‑agent, la coordinazione produce rendimenti decrescenti o negativi. Secondo: c’è un trade‑off tra tool use e coordinazione: a budget computazionale fissato, task “tool‑heavy” soffrono in modo sproporzionato l’overhead del multi‑agente, perché ogni turno in più compete con i token di ragionamento.
Che cosa cambia per le imprese: dal “prompt” al processo
Il punto non è “adottare agenti”, ma trasformare un task in un sistema operativo: strumenti, permessi, controlli, metriche. In questo passaggio molte aziende scoprono un vincolo: l’agente non è un chatbot, è un attore con privilegi. Quindi la domanda corretta è: quali privilegi concedo, con quali prove, e con quale rollback?
Qui entra la lettura più utile del paper: scegliere architettura è una decisione di governance e di economia della coordinazione, non solo di tecnologia. Per questo le metriche proposte (efficienza, overhead, ridondanza, message density, error amplification) sono più vicine all’ingegneria dei processi che alla “valutazione LLM” tradizionale.
Sul piano economico, l’unità di misura che evita auto‑inganni non è “costo per token”, ma costo per task riuscito. Lo studio usa misure che legano output e consumo (es. Success/1K tokens) per confrontare architetture che “parlano” di più (Fonte: Kim et al., 2025, Tab. 5). In azienda la versione operativa è: costo cloud + costo tool + costo umano di rework, normalizzato su completamento end‑to‑end.
Box — Un criterio pratico per non farsi sedurre dal “multi‑agente” Governare: decidere quali task sono eleggibili e quali dati possono toccare. Progettare: spezzare il lavoro in passi verificabili, con interfacce chiare tra passi. Eseguire: instrumentare tutto (log, permessi, rollback), perché senza evidenze non c’è controllo. |
Tre opzioni architetturali (e organizzative) per partire
Se si prende sul serio la soglia di complessità, le opzioni non sono “quale vendor”, ma “quale forma organizzativa per il ragionamento”. Una lettura utile del paper è che il multi‑agente funziona quando assomiglia a una fabbrica snella: flussi corti, controlli in punti critici, poche eccezioni. Quando assomiglia a un comitato, il costo sale e la qualità non è garantita.
Opzione 1 — Single‑agent con strumenti (SAS). È l’architettura di default per processi ripetibili e output verificabili: un agente, tool ben delimitati, poche chiamate “irreversibili”. È anche l’opzione che massimizza il ritorno per token nello studio (Success/1K tokens = 67,7; Periodo: esperimenti; Fonte: Kim et al., 2025, Tab. 5). Organizzativamente equivale a un “copilota” di funzione con controlli a valle.
Opzione 2 — Team parallelo con sintesi (Independent). Utile quando il task si spezza in sotto‑task realmente indipendenti (ricerca, comparazione, raccolta evidenze). È la forma più facile da prototipare, ma è anche quella che può amplificare l’errore se manca un quality gate (Ae = 17,2×; Fonte: Kim et al., 2025, Tab. 5). Organizzativamente: più analisti che lavorano in parallelo, ma serve una funzione di revisione che non sia solo “un’altra risposta”.
Opzione 3 — Orchestrazione (centralizzata o ibrida). Serve quando dovete combinare più strumenti, più politiche e più responsabilità: un orchestratore che assegna compiti e impone vincoli. È la forma più compatibile con segregazione dei doveri, ma porta overhead alto (O% 285 centralizzato, 515 ibrido; Fonte: Kim et al., 2025, Tab. 5). Organizzativamente: una “piattaforma agenti” interna che standardizza toolchain, logging e guardrail, con team di dominio che costruiscono workflow per singolo processo.
Nota su vendor e modelli. Lo studio istanzia le architetture su tre famiglie di LLM e riporta una misura di “capability” non agentica basata su un indice composito (Artificial Analysis Intelligence Index) (Fonte: Kim et al., 2025, Tab. 6; Artificial Analysis, metodologia). Per le imprese questo è un promemoria: la scelta del modello conta, ma non risolve l’overhead di coordinazione.
Tre dyad che vale la pena rendere esplicite (prima che si cristallizzino in architettura): (a) centralizzazione vs autonomia (chi decide e chi può agire), (b) velocità vs controllabilità (quanta frizione accettate per avere auditabilità), (c) riuso piattaforma vs specificità di processo (standard unico o soluzioni “ad hoc”). Per ciascuna dyad conviene dichiarare che tipo di relazione volete tra persone e agenti: “viva” (aumenta competenze e decisioni umane), “neutra” (esegue con supervisione), o “estrattiva” (scarica lavoro senza costruire capacità interna). Non è filosofia: è un modo rapido per allineare IT, operations e risk prima di scrivere codice.

Piano 30‑60‑90: decidere presto, misurare sempre
Un errore frequente è partire da un POC “a demo” e scoprire in produzione che la parte difficile era la governance dei tool e dei dati. Un piano 30‑60‑90 sensato, coerente con i risultati del paper, fa due cose: (i) seleziona task sotto soglia (decomponibili), (ii) costruisce osservabilità prima della scala.
Se il primo mese non produce log e metriche comparabili tra architetture, non state costruendo un sistema: state collezionando aneddoti. Le metriche minime da mettere in dashboard (con owner e soglie) sono: completamento end‑to‑end senza rework umano, tasso di escalation a umano, incidenti di non‑conformità/uso dati, errore fattuale/materiale con impatto, costo operativo per task riuscito, aderenza ai controlli.

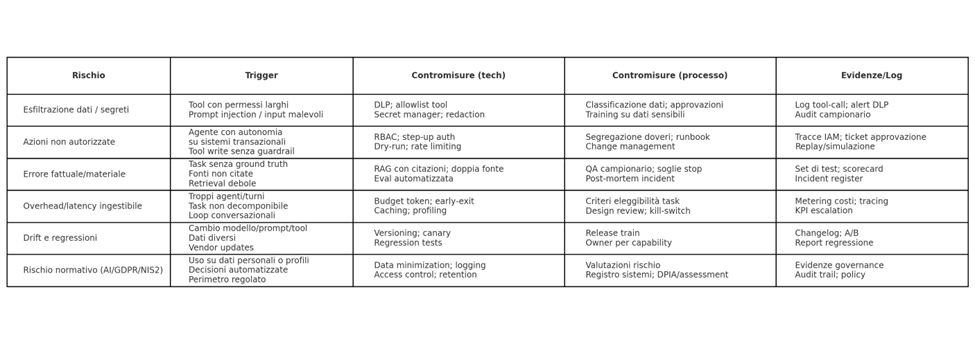
Matrice rischi‑contromisure: dove si rompe davvero
Con “compliance focus medio”, l’obiettivo non è scrivere un manuale legale ma evitare due fallimenti: (1) agenti che fanno cose non autorizzate, (2) agenti che producono output non auditabili. Qui la regolazione europea e i framework tecnici funzionano come check‑list: AI Act (Reg. UE 2024/1689), NIS2 (Dir. UE 2022/2555), NIST AI RMF e OWASP Top 10 per applicazioni LLM (Fonte: EUR‑Lex; NIST; ENISA; OWASP).
In pratica, la compliance “media” si traduce in quattro prove documentali: (i) policy dati e finalità, (ii) controllo accessi e segregazione dei doveri, (iii) logging end‑to‑end (prompt, tool call, output, versioni), (iv) processo di gestione incidenti e change. Il resto — classificazioni e obblighi specifici — dipende dal contesto di rischio e dal perimetro (Fonte: Reg. UE 2024/1689; Linee guida EDPB su decisioni automatizzate; ENISA su NIS2).
Cosa monitorare nel 2026 (se state investendo davvero)
Tre indicatori aiutano a evitare sorprese. Primo: le scadenze e l’implementazione dell’AI Act, perché impattano requisiti documentali e controlli, soprattutto su sistemi che incidono su persone o su funzioni regolamentate (Fonte: EUR‑Lex; EPRS, 2025).
Secondo: l’evoluzione delle capacità su documenti lunghi, tool use e valutazioni “office‑work”, perché spostano la frontiera dei task sottosoglia e cambiano il trade‑off tra SAS e MAS (Fonte: Kim et al., 2025).
Terzo: la maturità dei pattern di sicurezza per applicazioni LLM — prompt injection, output handling, supply chain, eccessiva autonomia — perché sono la differenza tra un agente “utile” e un agente “rischioso” (Fonte: OWASP LLM Top 10; NIST AI RMF).
Filo rosso
Il messaggio, alla fine, è più management che AI: scalare agenti significa scalare coordinazione. La coordinazione è una tecnologia costosa, e va meritata dal task. Se il lavoro è decomponibile, il multi‑agente può creare valore; se non lo è, aggiungere conversazioni aggiunge attrito. Il vantaggio competitivo non nasce dal “framework giusto”, ma dalla disciplina con cui scegliete processi eleggibili, costruite controlli e misurate il costo per task riuscito — prima che l’entusiasmo diventi spesa opaca.
Riferimenti
· Kim, Y., Gu, K., Park, C., Park, C., Schmidgall, S., Heydari, A. A., Yan, Y., Zhang, Z., Zhuang, Y., Liu, Y., Malhotra, M., Liang, P. P., Park, H. W., Yang, Y., Xu, X., Du, Y., Patel, S., Althoff, T., McDuff, D., & Liu, X. (2025). Towards a Science of Scaling Agent Systems. arXiv:2512.08296v2.
· Artificial Analysis. Intelligence benchmarking methodology e Artificial Analysis Intelligence Index (metodologia).
· Regolamento (UE) 2024/1689 (Artificial Intelligence Act), EUR‑Lex (OJ L 2024/1689).
· European Parliament Research Service (EPRS) (2025). AI Act implementation timeline (analisi e scadenze).
· Direttiva (UE) 2022/2555 (NIS2), EUR‑Lex.
· ENISA (2025). NIS2 Technical Implementation Guidance (cybersecurity risk management measures).
· NIST (2023). AI Risk Management Framework 1.0 (NIST AI 100‑1).
· OWASP. Top 10 for Large Language Model Applications (LLM Top 10).
· ISO/IEC 27001:2022 — Information security management systems (panoramica ISO).
· EDPB. Guidelines on Automated individual decision-making and Profiling (WP29/EDPB).
· ECB: key interest rates; euro reference exchange rates (USD). Eurostat: HICP euro area. EIA: Brent spot. Borsa Italiana/TradingView: FTSE MIB. Investing/TradingEconomics: BTP 10Y. FRED/Federal Reserve: serie di supporto (deposit facility; Brent; FX).



Commenti