Dall’immunità adattiva ai LLM: perché l’IA in azienda funziona solo se la tratti come un sistema che impara
- Andrea Viliotti

- 7 feb
- Tempo di lettura: 7 min
Il preprint di Sai T. Reddy (ETH Zurich/Botnar Institute of Immune Engineering) mette in parallelo quattro “convergenze” tra immunologia e intelligenza artificiale. Tradotte in chiave manageriale, indicano un’agenda: dati, feedback e governance prima degli slogan.
È una tentazione ricorrente: comprare un “copilota”, collegarlo ai documenti aziendali e aspettarsi che il valore emerga. Ma l’intelligenza artificiale in impresa non è un impianto, è un metabolismo. Funziona quando l’organizzazione costruisce un ciclo di apprendimento: che cosa conta come “vero”, chi decide cosa è “buono”, come si misura l’errore e come lo si riduce. Un recente preprint teorico di Sai T. Reddy, immunologo computazionale all’ETH Zurich, offre una lente insolita ma utile: la convergenza tra immunità adattiva e architetture moderne di IA.

Che cosa sostiene il paper (e che cosa no)
Il paper (“Computational Convergence of Adaptive Immunity and Artificial Intelligence”, bioRxiv, doi:10.64898/2026.02.03.703525) è dichiaratamente teorico: non introduce nuovi dati sperimentali. Propone invece una cornice di equivalenze e analogie computazionali tra il modo in cui il sistema immunitario seleziona anticorpi efficaci e il modo in cui i modelli di IA selezionano rappresentazioni utili. L’autore distingue due convergenze “esatte” (equazioni equivalenti) e due convergenze “strategiche” (strutture di progetto simili).

È importante anche ciò che il paper esplicita di non voler dire: l’equivalenza è “a livello algoritmico”, non un’identità fisica; non è un’argomentazione “teleologica” (nessuna natura che “progetta”); e non è un catalogo esaustivo (“non tutti i meccanismi immunitari hanno analoghi IA”). Per un’impresa, questa prudenza è già una lezione di governance: distinguere ciò che un modello è in grado di fare oggi da ciò che speriamo faccia domani, e mettere per iscritto i confini del claim.
Le due equivalenze: selezione e probabilità, non magia
La prima equivalenza collega l’attenzione dei Transformer alla distribuzione di Boltzmann: in forma semplificata, la softmax assegna un peso a ciascun “candidato” proporzionale a exp(score) e normalizza sulla somma. È una regola di selezione probabilistica: più un elemento è compatibile con la query, più influenza l’output. In azienda, questo si traduce in un punto pratico: se non definisci che cosa deve essere selezionato (documenti, procedure, dati autorizzati) e con quali criteri, stai delegando a un ranking opaco una parte del processo decisionale.
La seconda equivalenza riguarda il contrastive learning: l’obiettivo InfoNCE può essere letto come −log della probabilità di selezionare il “positivo” in mezzo a molti “negativi”. Anche qui, la domanda manageriale non è “quanto è bravo il modello”, ma “chi definisce positivi e negativi, con quale metodo”. Se un team non costruisce set di valutazione, casi d’uso, esempi di errore e definizioni operative di qualità, sta lasciando che l’apprendimento avvenga per inerzia (o peggio: per ottimizzazione di proxy non allineati al business).
L’adozione a stadi: una tabella che somiglia a un piano industriale
Nel paper, la gerarchia di addestramento dei grandi modelli (pre-training → fine-tuning → RLHF) viene messa in parallelo con tre fasi dell’affinity maturation nell’immunità adattiva (germline → ipermutazione somatica → selezione mediata da T follicular helper). L’analogia non serve per “romanzare” l’IA: serve per ricordare che l’efficacia non è un atto unico ma una sequenza. Un LLM non diventa affidabile perché “lo si accende”, ma perché si costruisce una pipeline che parte da capacità generali e arriva a preferenze locali, cioè a criteri di qualità specifici dell’impresa.

Tradotto in change management, significa: 1) fondazioni (alfabetizzazione, dati, policy e strumenti); 2) adattamento (piloti su processi concreti, integrazione nei flussi, ownership di business); 3) calibrazione (loop di feedback umano, revisione di policy, misurazione continua e audit). Saltare il terzo stadio è il modo più comune per trasformare un progetto IA in un generatore di “demo” senza istituzionalizzazione.
La memoria duale: perché RAG è più un tema di accesso che di modello
La quarta convergenza mette in parallelo l’architettura RAG (retrieval-augmented generation) con la “doppia memoria” del sistema immunitario: plasmacellule longeve (produzione stabile) e cellule B della memoria (richiamo rapido quando serve). Per un’impresa, la lezione è architetturale: una parte della conoscenza resta “nei parametri” (capacità linguistica, ragionamento, pattern), ma la conoscenza che deve essere aggiornata, tracciata e difesa sta nella memoria “a richiesta” — basi documentali, sistemi di record, policy, contratti.
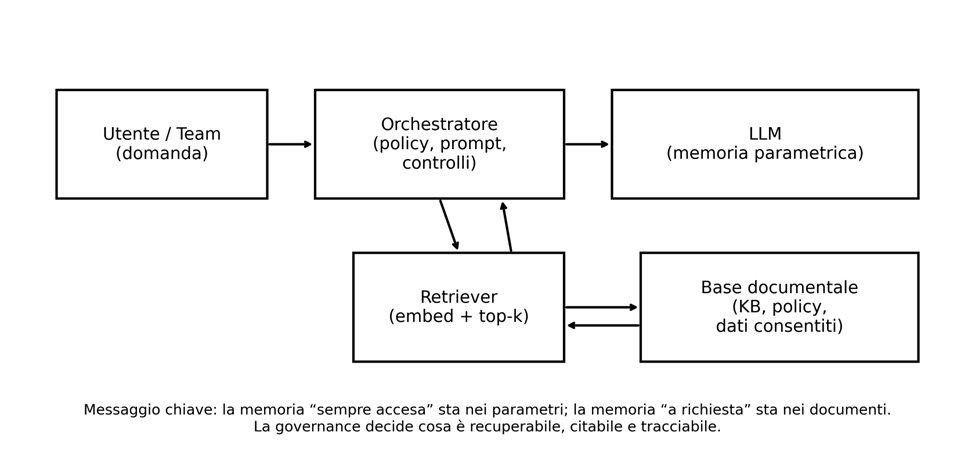
Qui la cultura aziendale pesa quanto l’infrastruttura: la stessa architettura può diventare un acceleratore di produttività o un rischio sistemico, a seconda di chi decide cosa è “recuperabile”, quali dati sono esclusi, come si logga l’uso e come si gestiscono incidenti. In altre parole: RAG non è un accessorio. È una politica di accesso travestita da feature.
Casi reali: dove si vede l’effetto (e dove si vedono i limiti)
Tre esempi, utili perché citabili e diversi per “maturità immunitaria” del ciclo di apprendimento:
• Klarna: l’assistente AI per il customer service. La società ha dichiarato che l’assistente ha gestito una quota significativa delle chat e ridotto i tempi medi; allo stesso tempo, il dibattito successivo su qualità e ribilanciamento uomo-macchina ricorda che la calibrazione delle preferenze (stadio 3) non è opzionale. (Fonti: comunicato Klarna; Reuters).
• Morgan Stanley: copilota interno su documentazione e ricerca. Il punto chiave non è il “prompt”, ma un framework di valutazione che misura affidabilità e coerenza prima di ampliare l’uso. (Fonti: OpenAI case study; comunicato Morgan Stanley).
• Sviluppo software: evidenze sperimentali su strumenti tipo Copilot mostrano guadagni di velocità in task controllati; il tema per le imprese è separare produttività locale (tempo di completamento) da qualità, sicurezza e debito tecnico. (Fonti: paper su arXiv; risultati sperimentali MIT/GenAI).
• Italia (banca): nei documenti pubblici di una grande banca si parla di adozione “responsabile e sicura” con guardrail e human-in-the-loop; il pezzo interessante è la governance del cambiamento (competenze, ruoli, presidi) più che il singolo tool. (Fonti: presentazioni/informativa della banca; Reuters sul contesto di trasformazione).
Framework GDE: l’IA come “Osservatore interno” da progettare
Nel framework GDE, un’organizzazione che adotta IA va letta come un “osservatore interno”: un sistema che percepisce, comprime informazione e agisce. La qualità dell’adozione non dipende solo dal modello, ma dalla vitalità del sistema di osservazione: canali di comunicazione chiari, feedback tracciabile, metrica condivisa di qualità, e capacità di correggere rotta senza “perdere coerenza”. In questa lente, l’IA è un amplificatore: se i canali sono vivi, accelera; se sono estrattivi (rumore, incentivi distorti, silos), amplifica errori e sfiducia.
Una tassonomia pratica, utile a board e C‑suite, è distinguere tre archetipi di adozione:
Adozione estrattiva. L’IA viene usata per tagliare costi e aumentare output senza ridefinire responsabilità, dati e controlli. Tipici segnali: assenza di evaluation harness, knowledge base “aperta”, incidenti ripetuti, fuga di competenze.
Adozione neutra. Si sperimentano tool e pilot, ma senza un ciclo stabile di apprendimento organizzativo. Tipici segnali: progetti che restano “proof of concept”, value non tracciato, governance intermittente.
Adozione “viva”. L’IA è integrata in un ciclo: dati → uso → feedback → correzione → audit. Tipici segnali: ownership di processo, misure di qualità e rischio, formazione e policy che cambiano con evidenza.
Box operativo — KPI per governare l’IA in azienda
Per evitare che l’IA resti un oggetto “narrativo”, servono KPI che separino: outcome (valore), leading (adozione e qualità del ciclo), rischio (incidenti) e cultura/change (qualità del feedback umano). Esempi operativi (adattare al contesto):
• Outcome: Tempo‑ciclo di un processo target attribuibile a workflow con IA (misura: BPM/ERP/CRM; confronto pre/post su processo definito).
• Leading: Adozione attiva per funzione: utenti attivi / utenti abilitati, e “profondità d’uso” (misura: log applicativi, audit accessi).
• Qualità: Tasso di correzione umana e categorie di errore (misura: review workflow, campionamento, rubriche).
• Risk: Incidenti di governance (data leakage, output non conforme, violazioni policy) e tempo di contenimento (misura: ticketing SOC/GRC).
• Cultura/Change: Frequenza e qualità del feedback strutturato (retrospettive, survey, “preference calibration” interna) e follow‑up sulle azioni correttive.
Checklist 30/60/90 giorni (decision‑first)
Una roadmap minima, pensata per imprese multi‑funzione (CEO/COO, CFO, CIO/CTO, HR, Legal‑Compliance):
30 giorni
– Definire 2–3 processi prioritari (costi/ricavi/rischio) e nominare un owner di business per ciascuno.
– Stabilire policy dati e confini: cosa può entrare in un sistema IA, cosa no; log e tracciabilità minimi.
– Impostare una “rubrica di qualità” (che cosa è un output buono) e un set di test iniziale.
– Formazione mirata: alfabetizzazione su limiti (allucinazioni, bias) e responsabilità d’uso per i team coinvolti.
60 giorni
– Pilota con retrieval governato (RAG) su un perimetro chiuso: documenti approvati, aggiornati, versionati.
– Integrare il workflow di review: campionamento, doppia firma per output sensibili, escalation.
– Mettere in piedi un registro incidenti e un processo di remediation (come per sicurezza o qualità).
– Misurare KPI leading e qualità; decidere “stop/scale” su evidenze, non su entusiasmo.
90 giorni
– Stabilizzare lo stadio 3: loop di feedback (preferenze) e aggiornamento periodico di policy e knowledge base.
– Allargare a una seconda funzione solo se il primo ciclo è auditabile e ripetibile.
– Formalizzare governance: comitato leggero (business+IT+legal+HR), cadenza e responsabilità.
– Piano competenze: ruoli (product owner IA, data steward, risk owner), incentivi e percorsi.
Il Filo Rosso
Il filo rosso del paper di Reddy, per un imprenditore, non è l’analogia “romantica” tra biologia e software. È l’insistenza su tre parole: selezione, stadi, memoria. Selezione significa definire criteri e dati; stadi significa costruire un percorso che arriva alla calibrazione delle preferenze; memoria significa separare ciò che il modello “sa” da ciò che l’impresa deve governare e aggiornare. Chi mette in fila questi tre elementi trasforma l’IA in capacità organizzativa. Chi li ignora compra solo velocità, e spesso la paga con rischio.
Fonti essenziali
• Reddy, S.T. (2026). Computational Convergence of Adaptive Immunity and Artificial Intelligence. bioRxiv preprint, doi:10.64898/2026.02.03.703525 (posted 5 Feb 2026).
• Commissione europea (2024). “AI Act enters into force” e pagina di timeline applicativa dell’AI Act (consultate per data di entrata in vigore e scadenze).
• ISO/IEC 42001:2023 (Artificial intelligence management system).
• NIST (2023). AI Risk Management Framework (AI RMF 1.0).
• Klarna (2024) comunicato su AI assistant + Reuters (2024–2026) per contestualizzazione.
• OpenAI (case study) e comunicati Morgan Stanley (2024) su applicazioni interne di GenAI.



Commenti